연재 순서
- MySQL IN subquery 성능. IN sub query는 가급적 사용을 피하자
- IN() v.s. EXISTS v.s INNER JOIN
- INNER JOIN v.s. EXISTS 성능 비교 <= 현재 글
1:n 관계 테이블에서 INNER JOIN과 EXISTS 비교
샘플 데이터 (부서, 사원 테이블)
다음과 같은 부서, 사원 테이블과 데이터를 가정하자. 부서 테이블과 사원 테이블의 관계는 1:n로 가정하였다.
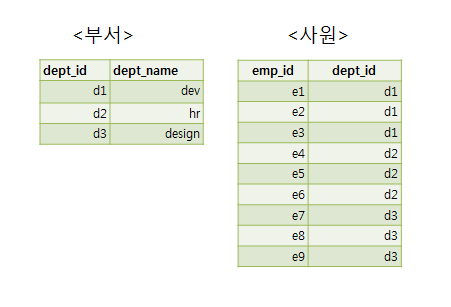
INNER JOIN
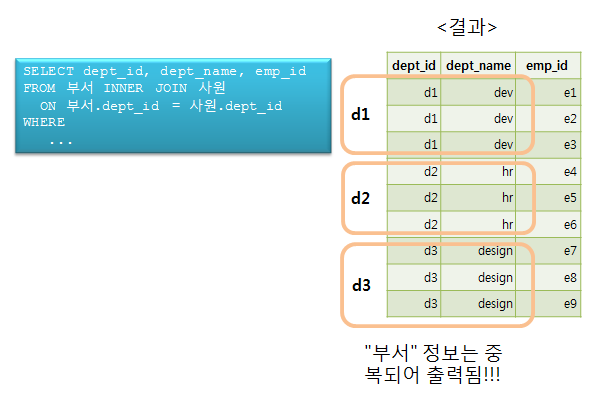
다음 그림은 INNER JOIN을 사용하여 부서 정보와 사원 정보를 출력하는 예이다. 1:n의 관계이기 때문에 결과는 n개가 출력되며 부서 정보는 반복되어 출력됨을 알 수 있다.
당신의 프로그램에서 출력해야 할 정보가 부서 정보만인 경우는 다음의 그림과 같이 DISTINCT를 사용해야 한다.
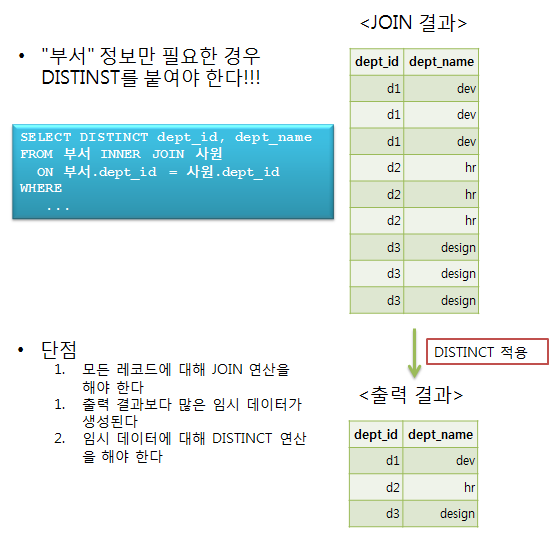
그림의 단점에 표현되었다시피 이렇게 INNER JOIN을 이용하여 1:n에서 1의 관계에 있는 테이블의 정보만 출력해야 하는 것은 비효율적이다. 그렇다면 EXISTS는 어떨까?
EXISTS
EXISTS의 경우는 inner query를 만족하는 레코드를 처음 만나는 순간 EXISTS가 true이므로 inner query를 더 이상 Evaluation하지 않는다. 이 점이 INNER JOIN과 EXISTS의 큰 차이이며 성능의 차이를 보인다. EXISTS가 어떻게 작동하는지 다음의 그림을 보도록 하자.

EXISTS v.s. INNER JOIN 실험 결과
질의
- 1990년대에 주문한 주문자의 이름 출력
우선 1990년대에 주문된 주문과 주문자 목록은 다음과 같이 출력할 수 있다.
SELECT orders.o_orderkey, orders.o_orderDATE, customer.c_name
FROM orders INNER JOIN customer ON orders.o_custkey = customer.c_custkey
WHERE orders.o_orderDATE BETWEEN '1991-01-01' AND '1999-12-31'
LIMIT 20;
+------------+-------------+--------------------+
| o_orderkey | o_orderDATE | c_name |
+------------+-------------+--------------------+
| 3868359 | 1992-08-22 | Customer#000000001 |
| 4273923 | 1997-03-23 | Customer#000000001 |
| 454791 | 1992-04-19 | Customer#000000001 |
| 4808192 | 1996-06-29 | Customer#000000001 |
| 579908 | 1996-12-09 | Customer#000000001 |
| 9747393 | 1997-09-22 | Customer#000000001 |
| 10221120 | 1994-12-22 | Customer#000000002 |
| 10888193 | 1996-11-10 | Customer#000000002 |
| 11626855 | 1998-06-03 | Customer#000000002 |
| 11760992 | 1997-12-30 | Customer#000000002 |
| 5133509 | 1996-07-01 | Customer#000000002 |
| 8108672 | 1995-01-16 | Customer#000000002 |
| 10068993 | 1996-07-10 | Customer#000000004 |
| 10294758 | 1994-12-18 | Customer#000000004 |
| 10651943 | 1997-11-04 | Customer#000000004 |
| 1071617 | 1995-03-10 | Customer#000000004 |
| 11418144 | 1996-10-17 | Customer#000000004 |
+------------+-------------+--------------------+
20 rows in set (0.00 sec)
위와 같이 출력을 하면 주문자 이름이 중복되어 출력되는데 이번 실험에서는 주문자 정보만 출력을 하려고 한다.
실험 결과
| 종류 | 수행시간(초) |
|---|---|
INNER JOIN |
13.00 |
INNER JOIN(개선된 버전) |
5.48 |
EXISTS |
3.67 |
실험 결과에서 알 수 있겠지만 이렇게 1:n의 관계에서 1에 있는 정보만 출력을 할 경우는 EXISTS가 빠른 것을 볼 수 있다.
INNER JOIN
SELECT COUNT(DISTINCT c_name)
FROM orders INNER JOIN customer
ON orders.o_custkey = customer.c_custkey
WHERE orders.o_orderDATE BETWEEN '1991-01-01'
AND '1999-12-31';
INNER JOIN (개선 버전)
INNER JOIN 개선 버전은 orders TABLE을 1:1로 만들기 위해 DISTINCT o_custkey로 유일한 고객 키만 추출을 하였다.
SELECT COUNT(c_name)
FROM (SELECT DISTINCT o_custkey
FROM orders
WHERE orders.o_orderDATE BETWEEN '1991-01-01'
AND '1999-12-31'
) orders INNER JOIN customer
ON orders.o_custkey = customer.c_custkey;
EXISTS
SELECT COUNT(c_name)
FROM customer WHERE EXISTS (
SELECT 1 FROM orders
WHERE orders.o_custkey = customer.c_custkey
AND orders.o_orderDATE
BETWEEN '1991-01-01' AND '1999-12-31'
);
“MySQL” 카테고리의 추천 글
- MySQL IN subquery 성능. IN sub query는 가급적 사용을 피하자
- MySQL의 IN() v.s. EXISTS v.s. INNER JOIN 성능 비교
- MySQL INNER JOIN v.s EXISTS 성능 비교
- JOIN에서 중복된 레코드 제거하기
- MySQL 중복 레코드 관리 방법 - INSERT IGNORE, REPLACE INTO, ON DUPLICATE UPDATE
- MySQL GROUP BY 성능 최적화를 위한 INDEX 설계
- MySQL Query Cache를 빠르게 비우기
- MySQL Plugin에 대한 간단한 소개
- MySQL InnoDB Index Statistics
- MySQL Foreign key 사용 시 주의 사항 (Can’t create table (errno: 150))