연재 시리즈
- MySQL IN subquery 성능. IN sub query는 가급적 사용을 피하자 <= 현재 글
- IN() v.s. EXISTS v.s INNER JOIN
- INNER JOIN v.s. EXISTS 어떤 것이 언제 더 빠른가
들어가며
다른 RDBMS는 모르겠지만 MySQL에서 IN subquery의 성능은 별로 좋지를 못하다. 본 글에서는 IN Subquery의 작동 방식을 살펴볼 것이다.
Data는 TPC-H 벤치마크 데이터를 이용하여 실험하였다. TPC-H 데이터를 MySQL에 Loading하는 것은 필자가 작성한 글을 보기 바란다.
본 글은 MySQL 5.5를 기준으로 작성되었다. MySQL 5.6에서는 subquery materialization을 이용하여 IN subquery의 성능이 향상되었다. MySQL 5.6의 IN () 성능 측정 결과는 다른 포스트에 정리할 예정이다.
IN subquery는 속도가 느리다
다음과 같이 30만명의 고객(customer)와 300만개의 주문(orders)가 존재한다.
mysql> SELECT COUNT(*) FROM customer;
+----------+
| COUNT(*) |
+----------+
| 300000 |
+----------+
1 row in set (0.00 sec)
mysql> SELECT COUNT(*) FROM orders;
+----------+
| COUNT(*) |
+----------+
| 3000000 |
+----------+
1 row in set (0.46 sec)
우선 2명의 고객 정보를 조회했다.
mysql> SELECT c_custkey FROM customer LIMIT 2;
+-----------+
| c_custkey |
+-----------+
| 29 |
| 48 |
+-----------+
2 rows in set (0.00 sec)
이들이 주문한 주문 정보를 조회하는 것은 다음과 같이 조회하면 된다. o_custkey가 INDEX로 걸려있기 때문에 수행 속도가 무척 빠르다.
mysql> SELECT SQL_NO_CACHE o_orderkey FROM orders WHERE o_custkey IN (29, 48);
+------------+
| o_orderkey |
+------------+
| 1572644 |
| 2773829 |
| 3440902 |
| 5779717 |
| 6144551 |
| 9493348 |
| 9974083 |
+------------+
7 rows in set (0.00 sec)
하지만, 쿼리를 다음과 같이 변경하면 동일한 결과가 출력되지만 3.12초나 걸린다!
mysql> SELECT SQL_NO_CACHE o_orderkey
-> FROM orders
-> WHERE o_custkey IN
(SELECT c_custkey FROM customer WHERE c_custkey IN (29, 48));
+------------+
| o_orderkey |
+------------+
| 1572644 |
| 2773829 |
| 3440902 |
| 5779717 |
| 6144551 |
| 9493348 |
| 9974083 |
+------------+
7 rows in set (3.12 sec)
어떻게 된 것일까?
IN subquery 작동 방식
아쉽게도 IN subquery는 우리가 생각하는데로 작동하지 않는다. 우리의 생각에는 다음 그림처럼 작동할 것 같으나 그렇지 않다.
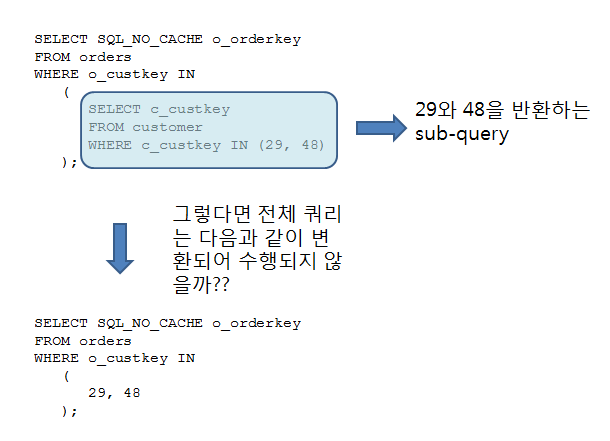
그렇지 않다는 것이 문제이다.
IN (상수)의 EXPLAIN 결과
우선 subquery를 사용하지 않을 때의 EXPLAIN 결과를 보자
mysql> EXPLAIN SELECT SQL_NO_CACHE o_orderkey FROM orders WHERE o_custkey IN (29, 48);
+----+-------------++-----------+---------+------+------+--------------------------+
| id | select_type || key | key_len | ref | rows | Extra |
+----+-------------++-----------+---------+------+------+--------------------------+
| 1 | SIMPLE || o_custkey | 4 | NULL | 8 | Using where; Using index |
+----+-------------++-----------+---------+------+------+--------------------------+
1 row in set (0.00 sec)
예상했던 대로 INDEX를 잘 타고 있다.
IN subquery의 EXPLAIN 결과
이번에는 IN subquery의 EXPLAIN 결과이다.
mysql> EXPLAIN SELECT SQL_NO_CACHE o_orderkey
-> FROM orders
-> WHERE o_custkey IN
-> (SELECT c_custkey FROM customer WHERE c_custkey IN (29, 48));
+----+--------------------+----------++-----------+---------+---------+--------------------------+
| id | select_type | table || key | key_len | rows | Extra |
+----+--------------------+----------++-----------+---------+---------+--------------------------+
| 1 | PRIMARY | orders || o_custkey | 4 | 3001636 | Using where; Using index |
| 2 | DEPENDENT SUBQUERY | customer || PRIMARY | 4 | 1 | Using index; Using where |
+----+--------------------+----------++-----------+---------+---------+--------------------------+
2 rows in set (0.00 sec)
어떤가? 당신은 어떤지 모르겠으나 내가 생각했던 결과와는 완전히 다르다. orders 테이블에 ‘Using index’가 있지만 rows가 3001636이나 되기 때문에 Full Scan을 하였다고 보면된다.
IN 안에 사용된 subquery가 “DEPENDENT SUBQUERY”로 출력되었다. MySQL의 EXPLAIN 결과에서 DEPENDENT 가 나오면 일단 느리다고 생각하면 된다.
“DEPENDENT SUBQUERY”란?
한국말로 번역하면 “의존적 서브쿼리”가 된다. 뭐에 의존적이냐. 상위 테이블 결과에 의존적이라는 이야기이며, 상위 테이블의 매 레코드마다 1번씩 subquery 결과와 비교를 하게 된다. (물론 위처럼 correlated query가 아닌 경우 subquery이 결과 자체 1번만 수행되고 그 결과는 임시 테이블에 저장된다.)
결국 orders 테이블에 IN subquery 이외의 조건이 없으므로 orders 테이블의 300만개 레코드를 모두 가져와서 o_custkey가 29 혹은 48인지 비교하는 방식으로 작동하기 때문에 속도가 느린 것이다.
단순하게 생각했을 때는 subquery가 먼저 수행되고 그 결과가 orders 테이블과 JOIN될 줄 알았는데 그 반대로 작동했다.
IN subquery의 회피 방법
- IN ()은 INNER JOIN 혹은 EXISTS로 변환 가능하다.
- NOT IN()은 LEFT OUTER JOIN 혹은 NOT EXISTS로 변환가능하다
MySQL 5.6에서 IN subquery 최적화 방법
이건 다음 기회에 정리…
“MySQL” 카테고리의 추천 글
- MySQL IN subquery 성능. IN sub query는 가급적 사용을 피하자
- MySQL의 IN() v.s. EXISTS v.s. INNER JOIN 성능 비교
- MySQL INNER JOIN v.s EXISTS 성능 비교
- JOIN에서 중복된 레코드 제거하기
- MySQL 중복 레코드 관리 방법 - INSERT IGNORE, REPLACE INTO, ON DUPLICATE UPDATE
- MySQL GROUP BY 성능 최적화를 위한 INDEX 설계
- MySQL Query Cache를 빠르게 비우기
- MySQL Plugin에 대한 간단한 소개
- MySQL InnoDB Index Statistics
- MySQL Foreign key 사용 시 주의 사항 (Can’t create table (errno: 150))