안내
https://dataengweekly.com/ 라는 사이트에서는 데이터 엔지니어링 글들을 묶어서 매주 1회 news letter를 발생하고 있습니다.
저는 315회부터 받기 시작했습니다. 뉴스레터를 요약한 포스팅을 저도 매주 1회 올려볼까 노력 중입니다.
뉴스레터를 구독하실 분은 https://dataengweekly.com/ 에 방문하시어 이메일 주소를 입력하시면 됩니다.
이슈 #316
Datadog에서 Kafka 운영 경험을 공유하다
https://www.datadoghq.com/blog/kafka-at-datadog/
Datadog에서는 40개 이상의 Kafka 클러스터를 운영 중이라고 한다. 1일에 총 1조개의 메시지를 처리한다고 하는데, 1조를 86400초로 나누니깐 1,157만건이나 되는 어마어마한 양이다. 이걸 다시 40대 클러스터로 나누면 클러스터당 1초 평균 289만건 처리. 이것도 대단한 양이네.
아래와 같은 내용을 설명한다고 한다.
- The importance of coordinating changes to the maximum message size
- Unclean leader elections: To enable or not to enable?
- Investigating data reprocessing issues on our low-throughput topics
- Why low-traffic topics can retain data longer than expected
kafka4s - Functional programming with Kafka and Scala
https://banno.github.io/kafka4s/
주로 Spark Streaming을 이용해서 Kafka에 메지시를 읽고 쓰다보니 Kafka API를 직접 사용하는 일은 없었다. Scala에서 Kafka API를 직접 사용할 일이 있을지 모르겠는데, 그때가 되면 kafka4s를 사용해봐도 될 듯.
Schema Registry, Avro, case class 등을 함께 사용하기 위한 편의성을 제공하는 듯 하다.
Distributed Tracing — we’ve been doing it wrong
https://medium.com/@copyconstruct/distributed-tracing-weve-been-doing-it-wrong-39fc92a857df
분산 트레이싱에 대한 소개와 insight를 위한 visualization에 대한 문서이다.
뉴스레더에는 UX에 대한 글이라고 소개되어 있는데, 정작 글안에는 UX에 관한 그림 한장 없네.
Elasticsearch 1.7에서 6.7로 업그레이드 경험기
https://blog.devartis.com/how-we-upgraded-a-10-tb-elasticsearch-cluster-from-1-7-to-6-7-466f6a33a6ca
10TB 짜리 ES 1.7 cluster를 6.7로 업그레이드한 경험을 설명한다.
버전을 올린 후로 응답 시간이 34% 줄었다고 한다. Disk 사용량은 50%로 줄고.
Apache Spark 2.3 - native & vectorized Apache ORC file reader
https://medium.com/@ylashin/benchmarking-orc-improvements-in-spark-2-3-a1f818a0a989
아직 Spark 2.3나 2.4에 어떤 기능이 추가되었는지 모르고 있었다. (현업에서는 아직 Spark 2.2를 주로 사용하기 때문이기도 하지만, 새로운 기능을 찾아보지도 않은 나의 안이함도 문제)
Spark 2.3 이전에는 Parquet를 주로 미는 것 같은 느낌이 있었고, ORC 관련 코드는 Hive 쪽 코드를 가져다가 쓴 것 같다 (작년인가 언뜻 듣기에는 Hive 쪽에서 Databricks 쪽에 자기들 코드 가져다 쓰지 말라고 했다는 걸 들은 것도 같고)
그래서 Spark 2.3부터는 ORC를 읽는 자체 코드를 개발했고, 거기에 vectorize 까지 구현을 했다고 한다.
그랬더니 성능이 아래처럼 나왔다 (lower is better)
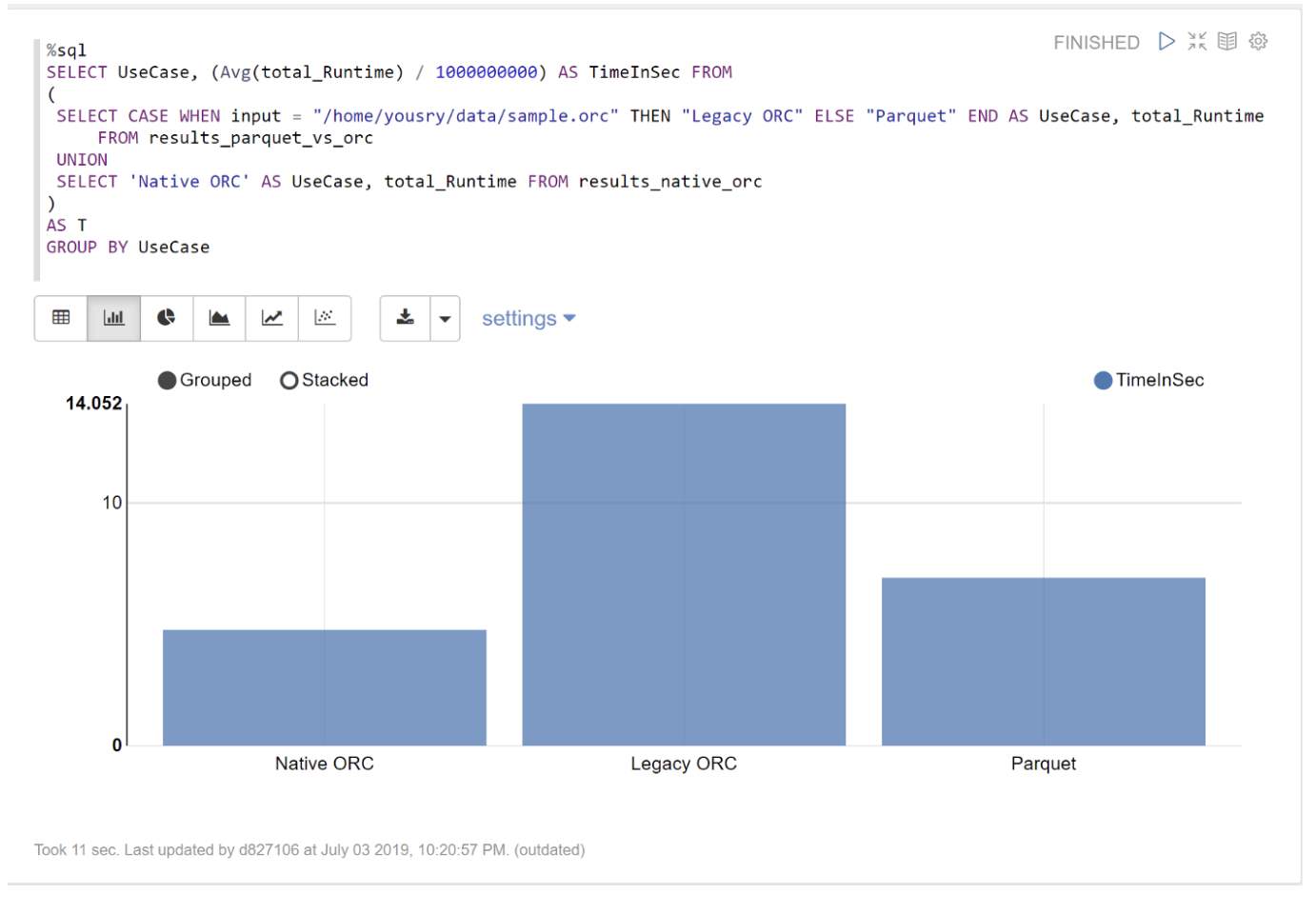
이젠 Parquet보다 ORC가 더 빠르다.
- old ORC reader: 14초
- Parquet reader: 6.9초
- vectorized ORC reader: 4.77초 (parquet의 70% 수준)
Spark 2.4 이상부터는 ORC를 Spark의 기본 파일 포맷으로 하려는 계획이 있다고 한다.
나도 테스트해봐야겠다.
본 카테고리의 추천 글
- Kafka Unit Test with EmbeddedKafka
- Spark Structured Streaming에서의 Unit Test
- spark memoryOverhead 설정에 대한 이해
- Spark 기능 확장하기
- Spark DataFrame vs Dataset (부제: typed API 사용하기)
- Spark UI 확장하기
- Custom Spark Stream Source 개발하기
- Spark에서 Kafka를 batch 방식으로 읽기
- SparkSession의 implicit에 대한 이해
- spark-submit의 –files로 upload한 파일 읽기
- Scala case class를 Spark의 StructType으로 변환하기
- Spark on Kubernetes 사용법 및 secure HDFS에 접근하기
- Spark의 Locality와 getPreferredLocations() Method
- Spark Streaming의 History