HDFS에는 두 대의 Data Node가 존재하는데, 내가 읽을 파일은 host1에 존재한다. Spark에서 이 파일을 읽을 때, Spark Job은 host1로 제출되어야 Network Cost없이 파일을 빠르게 읽을 수 있을 것이다.
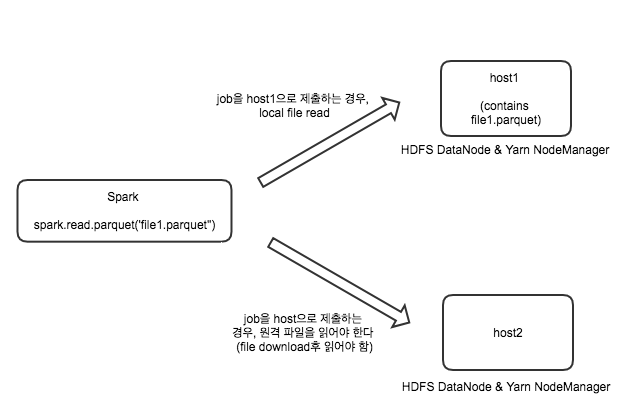
이런 Locality 정책이 항상 옳바른 것은 아니다. 그러한 예로 host1의 모든 Resource가 할당되어 있어서 Job을 띄울 수 없어서 대기해야 하는 경우가 있다. 이 경우, Job Submit을 대기하기 보다는 원격의 host에 Job을 띄워서 원격 read를 하는 것이 더 빠를 수도 있다.
이렇게 Locality를 맞추기 위해 얼마나 대기를 할지 결정하는 Spark 옵션이 spark.locality.wait이다. 기본 값은 3초이고, 3초 동안 Submit을 못한 경우 Locality를 희생하고 원격에 Job을 제출하게 된다.
그렇다면, 이러한 Locality는 어떻게 어떻게 보장될까? HDFS에 올려진 파일이라면, Spark이 자체적으로 hdfs API를 이용하여 file의 위치를 알 수 있겠지만 Data Source API를 이용해서 Custom Platform을 Spark에 연동한 경우 읽고자 하는 Data의 위치를 Spark이 알 수 없을 것이다.
Spark Data Source API에서 이러한 기능을 하는, 좀 더 일반적으로 이야기하자면 Partition이 존재하는 Host의 위치를 반환하는 함수가 getPreferrerLocations()이다.
Spark 2.2 기준으로 이렇게 생긴 함수이다. (출처: Github)
/**
* Optionally overridden by subclasses to specify placement preferences.
*/
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
즉, Partition을 넘기면 해당 Partition이 존재하는 host들의 목록을 반환한다. 분산처리 시스템에서는 복제가 중요하기 때문에 1개 Partition이 여러 개의 host에 나눠 저장되어 있을 수 있다. 이 때문에 함수 이름이 복수형이고, return value의 type도 Seq[String]처럼 여러 개을 return한다.
Custom Data Source들은 이를 어떻게 구현하고 있을까? 아래 Platform들이 Spark 연동을 어떻게 했는지 확인해보면 도움이 될 듯 하다. 물론 개별 Platform의 API를 알면 더 이해하기 쉽겠다.
Kudu
override def getPreferredLocations(partition: Partition): Seq[String] = {
partition.asInstanceOf[KuduPartition].locations
}
}
HadoopRDD
override def getPreferredLocations(split: Partition): Seq[String] = {
val hsplit = split.asInstanceOf[HadoopPartition].inputSplit.value
val locs = hsplit match {
case lsplit: InputSplitWithLocationInfo =>
HadoopRDD.convertSplitLocationInfo(lsplit.getLocationInfo)
case _ => None
}
locs.getOrElse(hsplit.getLocations.filter(_ != "localhost"))
}
Elasticearch Hadoop
override def getPreferredLocations(split: Partition): Seq[String] = {
val esSplit = split.asInstanceOf[EsPartition]
val ip = esSplit.esPartition.nodeIp
if (ip != null) Seq(ip) else Nil
}
본 카테고리의 추천 글
- Kafka Unit Test with EmbeddedKafka
- Spark Structured Streaming에서의 Unit Test
- spark memoryOverhead 설정에 대한 이해
- Spark 기능 확장하기
- Spark DataFrame vs Dataset (부제: typed API 사용하기)
- Spark UI 확장하기
- Custom Spark Stream Source 개발하기
- Spark에서 Kafka를 batch 방식으로 읽기
- SparkSession의 implicit에 대한 이해
- spark-submit의 –files로 upload한 파일 읽기
- Scala case class를 Spark의 StructType으로 변환하기
- Spark on Kubernetes 사용법 및 secure HDFS에 접근하기
- Spark의 Locality와 getPreferredLocations() Method
- Spark Streaming의 History