작년 9월에 (2023.09 기준) code 생성용 LLM들라는 글을 적었었다.
2024년 06월 기준으로도 적어본다. 워낙 발전 속도가 빠른 분야이다보니 9개월이 지난 현재 시점에서는 새롭고 더 성능 좋은 모델이 많이 나온 것으로 보인다.
본인도 아래에 있는 모델을 모두 테스트해본 것은 아닌 점을 밝힌다.
Llama 3 70B Instruct
2024.06 기준으로 chatbot arena leaderboard의 coding 분야에서 당당히 12 위를 차지하고 있다. 1위~11위는 모두 closed-weight model이므로 공개된 model 중에서는 Llama 3 70B Instruct가 1위이다.
출처: https://chat.lmsys.org/?leaderboard=
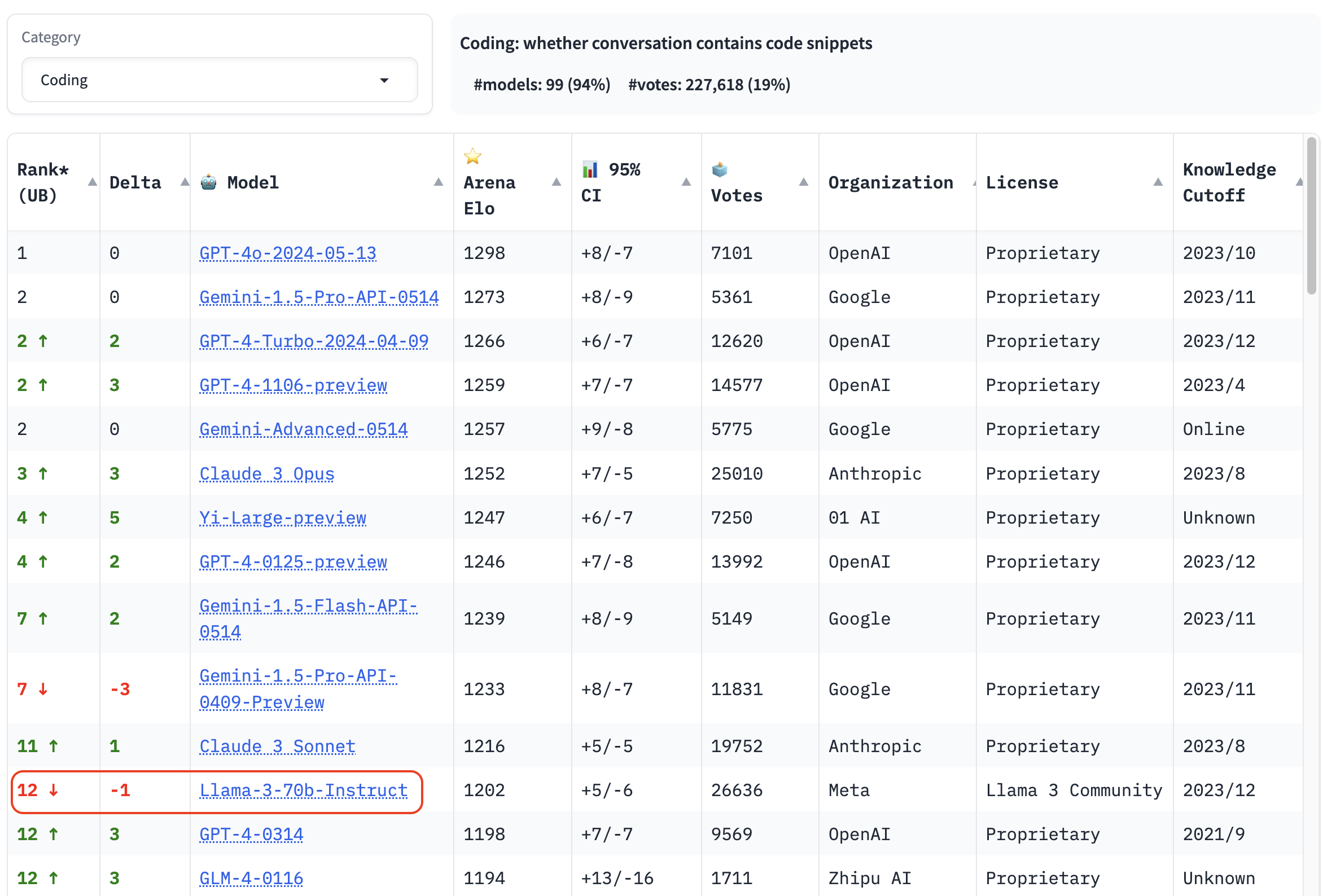
code 생성 전용 모델이 아님에도 점수가 꽤나 높다. 심지어 GPT-4-0314보다 순위가 높다.
Codestral
2024년 5월 29일에 발표된 아주 따끈따끈한 model이다. model size는 22B이다.
Llama 3 70B는 code 생성 전용 모델이 아니었지만 Codestral은 code를 많이 학습한 모델이다. 그래서 그런지 size가 22B임에도 Llama 3 70B Instruct보다 점수가 높다 (Codestral 개발사에서 측정한 점수라는 걸 감안하자)
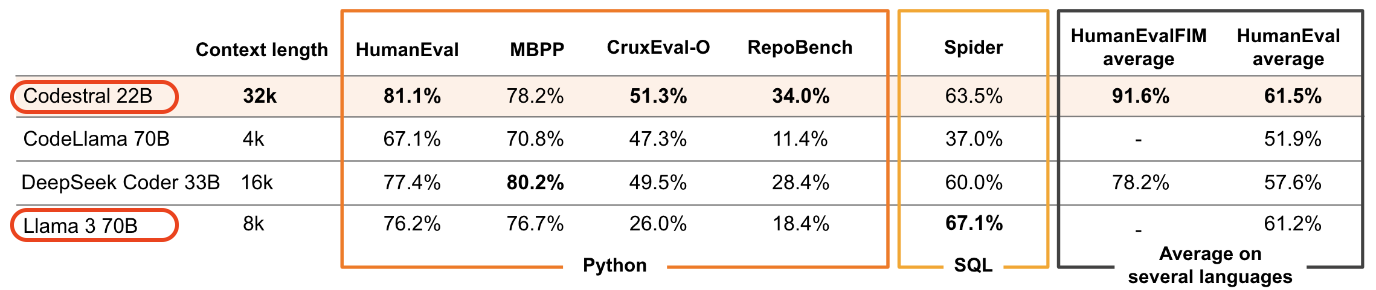
(출처: https://mistral.ai/news/codestral/)
leaderborad에서 점수를 보면 좋겠는데 아직 못 찾았다.
그런데 사람들 평은 무척 좋아보인다.
Codestral 발표이후 reddit에 다음과 같은 글이 올라왔는데 댓글이 많이 달렸으므로 궁금한 분들은 한번 읽어보자.
Codestral: Mistral AI first-ever code model
그리고 며칠 뒤에는 다음과 같은 제목의 글이 올라와 있다.
GPT-4o로 1시간이 걸려도 못 풀었던 것을 Codestral에서는 단 2줄로 풀었다고 한다.
AutoCoder
model size: 33B, 6.7B
reddit 글을 읽다가 알게된 model이다.
https://www.reddit.com/r/LocalLLaMA/comments/1d3qx5q
Abstract 내용만 보면 AutoCoder가 GPT-4 Turbo와 GPT-4o를 뛰어넘는다고 한다.
We introduce AutoCoder, the first Large Language Model to surpass GPT-4 Turbo (April 2024) and GPT-4o in pass@1 on the Human Eval benchmark test (90.9% vs. 90.2%).
code 생성 능력도 능력이지만 code interpreter 기능이 좋다고 한다.
In addition, AutoCoder offers a more versatile code interpreter compared to GPT-4 Turbo and GPT-4o
(근데 code interpreter는 model이 아니라 LLM과 상호 작용하는 agent일텐데, 어떤 점이 code interpreter 관점에서 AutoCoder model이 좋다는 것인지는 아직 잘 모르겠다)
base model은 DeepSeek Coder라고 한다.
CodeQwen 1.5
model size: 7B
위의 AutCoder reddit 댓글에서 알게된 모델이다.
size가 7B 밖에 안되는데 HumanEval+ 점수는 AutoCoder 33B보다 점수가 높다. (다만, +가 안 붙은 그냥 HumanEval에서는 AutoCoder 33B가 더 높다)
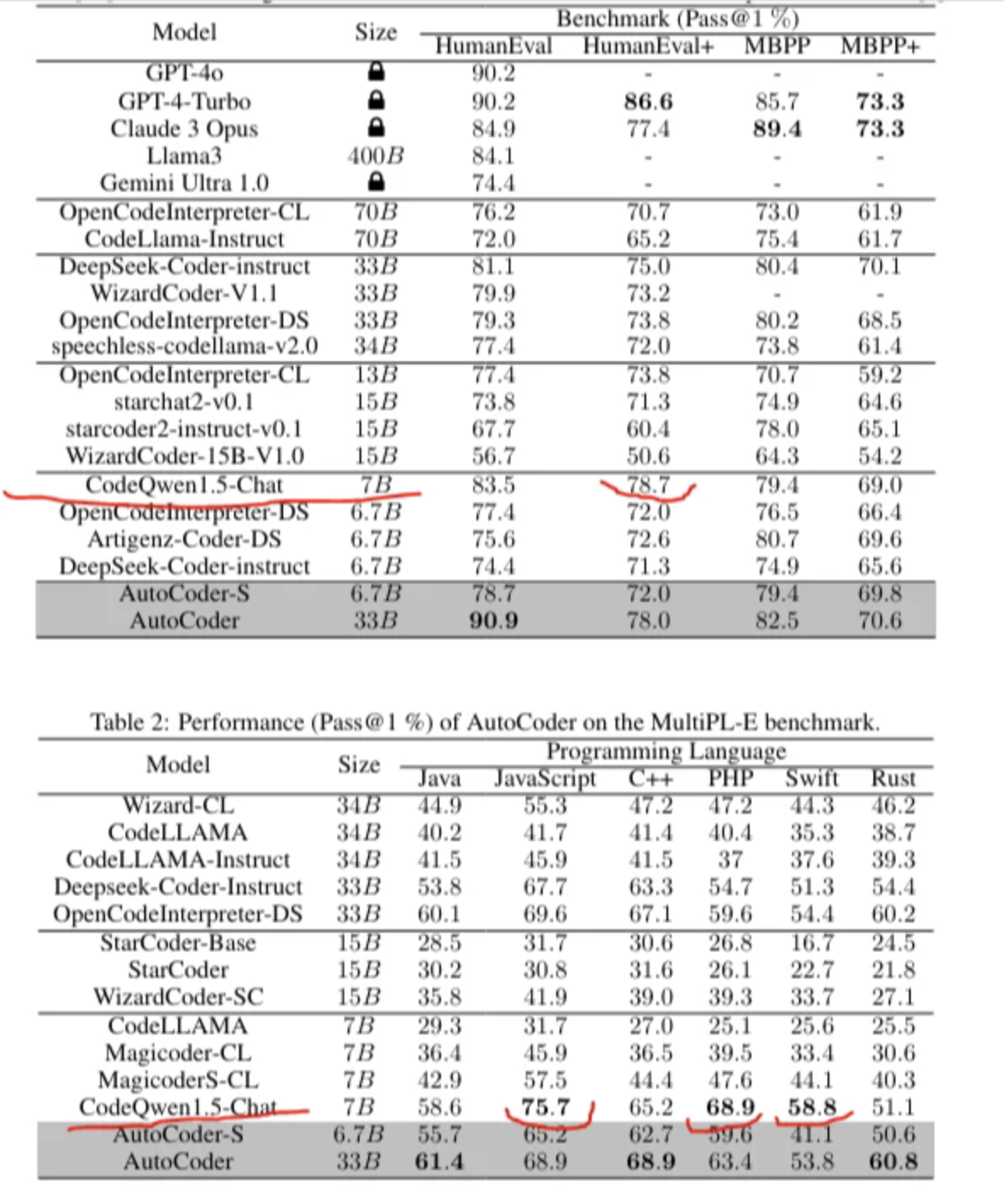
reddit 댓글 https://www.reddit.com/r/LocalLLaMA/comments/1d3qx5q 를 읽어보면 CodeQwen의 평가가 극과 극을 달리는 듯 하다.
- 댓글 1: “In my experience CodeQwen can produce great code and terrible one, on a random basis”
- 댓글 2: “Up until the release of gpt4o codeqwen was my go to model. It’s literally magic”
- 댓글 3: “I saw this chart and downloaded codeqwen to use with Contine as a Copilot alternative in VS code. It’s so bad. It can’t stick to the requests and generates stuff I don’t want. On the other hand, llama 3 70B is way better with the same prompts”
DeepSeek Coder
model size: 1.3B, 5.7B, 6.7B and 33B
요것도 꽤나 언급되는 모델로 보인다.
DeepSeek과 Qwen 둘다 중국 기업의 모델이다. 우리나라 기업의 모델이 안 보여 많이 아쉬웠다.